Fast Syndrome Based Hash
| General | |
|---|---|
| Designers | Daniel Augot, Matthieu Finiasz, Nicolas Sendrier |
| First published | 2003 |
| Derived from | McEliece cryptosystem and Niederreiter cryptosystem |
| Successors | Improved Fast Syndrome Based Hash Function |
| Related to | Syndrom-based Hash Function |
| Detail | |
| Digest sizes | Scalable |
In cryptography, the Fast Syndrome-based hash Functions (FSB) are a family of cryptographic hash functions introduced in 2003 by Daniel Augot, Matthieu Finiasz, and Nicolas Sendrier. [1] Unlike most other cryptographic hash functions in use today, FSB can to a certain extent be proven to be secure. More exactly, it can be proven that breaking FSB is at least as difficult as solving a certain NP-complete problem known as Regular Syndrome Decoding. We call function with these properties provably secure. Though it is not known whether NP-complete problems are solvable in polynomial time, it is often assumed that they are not.
Several versions of FSB have been proposed, the latest of which was submitted to the SHA-3 cryptography competition but was rejected in the first round. Though all versions of FSB claim provable security, some preliminary versions were eventually broken. [2] The design of the latest version of FSB has however taken this attack into account and remains secure to all currently known attacks.
As usual, provably security does come at a cost. FSB is slower than traditional hash functions and uses quite a lot of memory, which makes it impractical on memory constrained environments. Furthermore, the compression function used in FSB needs a large output size to guarantee security. This last problem is has been solved in recent versions by simply compressing the output by another compression function called Whirlpool. However, though the authors argue that adding this last compression does not reduce security, it makes a formal security proof impossible. [3]
Contents |
Description of the hash function
We start with a compression function 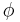 with parameters
with parameters  such that
such that  and
and  . This function will only work on messages with length
. This function will only work on messages with length  ;
; 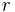 will be the size of the output. Furthermore, we want
will be the size of the output. Furthermore, we want 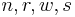 and
and 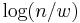 to be natural numbers, where
to be natural numbers, where 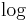 denote the binary logarithm. The reason for
denote the binary logarithm. The reason for 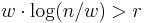 is that we want to be a compression function, so the input must be larger than the output. We will later use the Merkle-Damgård construction to extend the domain to inputs of arbitrary lengths.
is that we want to be a compression function, so the input must be larger than the output. We will later use the Merkle-Damgård construction to extend the domain to inputs of arbitrary lengths.
The basis of this function consists of a (randomly chosen) binary 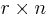 matrix
matrix  which acts on a message of
which acts on a message of  bits by matrix multiplication. Here we encode the
bits by matrix multiplication. Here we encode the 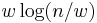 -bit message as a vector in
-bit message as a vector in 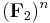 , the -dimensional vector space over the field of two elements, so the output will be a message of bits.
, the -dimensional vector space over the field of two elements, so the output will be a message of bits.
For security purposes as well as to get a faster hash speed we want to use only “regular words of weight 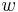 ” as input for our matrix.
” as input for our matrix.
Definitions
- A message is called a word of weight and length if it consists of bits and exactly of those bits are ones.
- A word of weight and length is called regular if in every interval
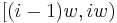 it contains exactly one nonzero entry for all
it contains exactly one nonzero entry for all 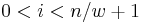 . More intuitively, this means that if we chop up the message in w equal parts, then each part contains exactly one nonzero entry.
. More intuitively, this means that if we chop up the message in w equal parts, then each part contains exactly one nonzero entry.
The Compression Function
There are exactly 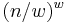 different regular words of weight and length , so we need exactly
different regular words of weight and length , so we need exactly 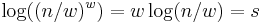 bits of data to encode these regular words. We fix a bijection from the set of bit strings of length
bits of data to encode these regular words. We fix a bijection from the set of bit strings of length 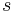 to the set of regular words of weight and length and then the FSB compression function is defined as follows:
to the set of regular words of weight and length and then the FSB compression function is defined as follows:
- input: a message of size
- convert to regular word of length and weight
- multiply by the matrix
- output: hash of size
This version is usually called Syndom Based Compression. It is very slow and in practice done in a different and faster way resulting in Fast Syndrom Based Compression. We split into sub-matrices 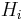 of size
of size 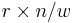 and we fix a bijection from the bit strings of length to the set of sequences of numbers between 1 and
and we fix a bijection from the bit strings of length to the set of sequences of numbers between 1 and 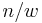 . This is equivalent to a bijection to the set of regular words of length and weight , since we can see such a word as a sequence of numbers between 1 and . The compression function looks as follows:
. This is equivalent to a bijection to the set of regular words of length and weight , since we can see such a word as a sequence of numbers between 1 and . The compression function looks as follows:
- Input: message of size
- Convert to a sequence of numbers
 between 1 and
between 1 and - Add the corresponding columns of the matrices to obtain a binary string a length
- Output: hash of size
We can now use the Merkle-Damgård construction to generalize the compression function to accept inputs of arbitrary lengths.
Example of the compression
Situation and initialization: Hash a message 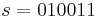 using
using 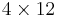 matrix H
matrix H
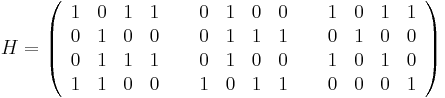
that is separated into 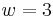 sub-blocks
sub-blocks  ,
,  ,
, 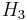 .
.
Algorithm:
- We split the input into parts of length
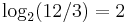 and we get
and we get 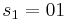 ,
, 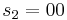 ,
, 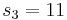 .
. - We convert each
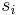 into an integer and get
into an integer and get 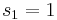 ,
, 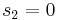 ,
, 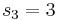 .
. - From the first sub-matrix , we pick the column 2, from the second sub-matrix the column 1 and from the third sub-matrix the column 4.
- We add the chosen columns and obtain the result
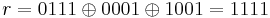 .
.
Security Proof of FSB
The Merkle-Damgård construction is proven to base its security only on the security of the used compression function. So we only need to show that the compression function is secure.
A cryptographic hash function needs to be secure in three different aspects:
- Pre-image resistance: Given a Hash h it should be hard to find a message m such that Hash(m)=h
- Second pre-image resistance: Given a message m1 it should be hard to find a message m2 such that Hash(m1) = Hash(m2)
- Collision resistance: It should be hard to find two different messages m1 and m2 such that Hash(m1)=Hash(m2)
Note that if an adversary can find a second pre-image, than he can certainly find a collision. This means that if we can prove our system to be collision resistant, it will certainly be second-pre-image resistant.
Usually in cryptography hard means something like “almost certainly beyond the reach of any adversary who must be prevented from breaking the system”. We will however need a more exact meaning of the word hard. We will take hard to mean “The runtime of any algorithm that finds a collision or pre-image will depend exponentially on size of the hash value”. This means that by relatively small additions to the hash size, we can quickly reach high security.
Pre-image resistance and Regular Syndrome Decoding (RSD)
As said before, the security of FSB depends on a problem called Regular Syndrome Decoding (RSD). Syndrome Decoding is originally a problem from coding theory but its NP-Completeness makes it a nice application for cryptography. Regular Syndrome Decoding is a special case of Syndrome Decoding and is defined as follows:
Definition of RSD: Given matrices of dimension 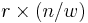 and a bit string
and a bit string 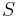 of length such that there exists a set of columns, one in each , summing to . Find such a set of columns.
of length such that there exists a set of columns, one in each , summing to . Find such a set of columns.
This problem has been proven to be NP-Complete by a reduction from 3-dimensional matching. Again, though it is not known whether there exist polynomial time algorithms for solving NP-Complete problems, none are known and finding one would be a huge discovery.
It is easy to see that finding a pre-image of a given hash is exactly equivalent to this problem, so the problem of finding pre-images in FSB must also be NP-Complete.
We still need to prove collision resistance. For this we need another NP-Complete variation of RSD: 2-Regular Null Syndrome Decoding.
Collision resistance and 2-Regular Null Syndrome Decoding (2-NRSD)
Definition of 2-NRSD: Given matrices of dimension and a bit string of length such that there exists a set of 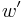 columns, two or zero in each , summing to zero.
columns, two or zero in each , summing to zero. 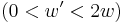 . Find such a set of columns.
. Find such a set of columns.
2-NRSD has also been proven to be NP-Complete by a reduction from 3-dimensional matching.
Just like RSD is in essence equivalent to finding a regular word such that 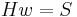 , 2-NRSD is equivalent to finding a 2-regular word such that
, 2-NRSD is equivalent to finding a 2-regular word such that 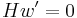 . A 2-regular word of length and weight is a bit string of length such that in every interval exactly two or zero entries are equal to 1. Note that a 2-regular word is just a sum of two regular words.
. A 2-regular word of length and weight is a bit string of length such that in every interval exactly two or zero entries are equal to 1. Note that a 2-regular word is just a sum of two regular words.
Suppose that we have found a collision, so we have Hash(m1) = Hash(m2) with 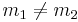 . Then we can find two regular words
. Then we can find two regular words 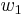 and
and 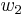 such that
such that 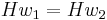 . We then have
. We then have 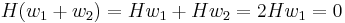 ;
; 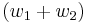 is a sum of two different regular words and so must be a 2-regular word of which the hash is zero, so we have solved an instance of 2-NRSD. We conclude that finding collisions in FSB is at least as difficult as solving 2-NRSD and so must be NP-Complete.
is a sum of two different regular words and so must be a 2-regular word of which the hash is zero, so we have solved an instance of 2-NRSD. We conclude that finding collisions in FSB is at least as difficult as solving 2-NRSD and so must be NP-Complete.
The latest versions of FSB use the compression function Whirlpool to further compress the hash output. Though this cannot be proven, the authors argue that this last compression does not reduce security. Note that even if one were able to find collisions in Whirlpool, one would still need to find the collisions pre-images in the original FSB compression function to find a collision in FSB.
Examples
Solving RSD, we are in the opposite situation as when hashing. Using the same values as in the previous example, we are given separated into sub-blocks and a string 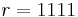 . We are asked to find in each sub-block exactly one column such that they would all sum to . The expected answer is thus , , . This is known to be hard to compute for large matrices.
. We are asked to find in each sub-block exactly one column such that they would all sum to . The expected answer is thus , , . This is known to be hard to compute for large matrices.
In 2-NRSD we want to find in each sub-block not one column, but two or zero such that they would sum up to 0000 (and not to ). In the example, we might use column (counting from 0) 2 and 3 from , no column from column 0 and 2 from . More solutions are possible, for example might use no columns from .
Linear cryptanalysis
The provable security of FSB means that finding collisions is NP-complete. But the proof is a reduction to a problem with asymptotically hard worst-case complexity. This offers only limited security assurance as there still can be an algorithm that easily solves the problem for a subset of the problem space. For example, there exists a linearization method that can be used to produce collisions of in a matter of seconds on a desktop PC for early variants of FSB with claimed 2^128 security. It is shown that the hash function offers minimal pre-image or collision resistance when the message space is chosen in a specific way.
Practical security results
The following table shows the complexity of the best known attacks against FSB.
| Output size (bits) | Complexity of collision search | Complexity of inversion |
|---|---|---|
| 160 | 2100.3 | 2163.6 |
| 224 | 2135.3 | 2229.0 |
| 256 | 2190.0 | 2261.0 |
| 384 | 2215.5 | 2391.5 |
| 512 | 2285.6 | 2527.4 |
Genesis
FSB is a speed-up version of Syndrom-based hash function (SB). In the case of SB the compression function is very similar to the encoding function of Niederreiter's version of McEliece cryptosystem. Instead of using the parity check matrix of a permuted Goppa code, SB uses a random matrix . From the security point of view this can only strengthen the system.
Other properties
- Both the block size of the hash function and the output size are completely scalable.
- The speed can be adjusted by adjusting the number of bitwise operations used by FSB per input bit.
- The security can be adjusted by adjusting the output size.
- Bad instances exist and one must take care when choosing the matrix .
- The matrix used in the compression function may grow large in certain situations. This might be a limitation when trying to use FSB on memory constrained devices. This problem was solved in the related hash function called Improved FSB, which is still provably secure, but relies on slightly stronger assumptions.
References
- ^ Augot, D.; Finiasz, M.; Sendrier, N. (2003), "A fast provably secure cryptographic hash function.", http://eprint.iacr.org/2003/230.pdf
- ^ Saarinen, Markku-Juhani O. (2007), "Linearization Attacks Against Syndrome Based Hashes", Progress in Cryptology – INDOCRYPT 2007
- ^ Finiasz, M.; Gaborit, P.; Sendrier, N. (2007), "Improved Fast Syndrome Based Cryptographic Hash Functions", ECRYPT Hash Workshop 2007, http://events.iaik.tugraz.at/HashWorkshop07/papers/Finiasz_ImprovedFastSyndromeBasedCryptographicHashFunction.pdf
External links
|
|||||||||||||||||||||||||||||||||||||||||